1. 로지스틱 회귀란 무엇인가?
로지스틱 회귀의 원리는 로지스틱 함수를 사용하여 선형 회귀의 결과(-Ø,Ø)를 (0,1)에 매핑하는 것이므로 먼저 선형 회귀 함수와 로지스틱 함수를 소개하고 이 섹션의 세 번째 부분에서 로지스틱 회귀 함수를 소개합니다.
1. 선형회귀함수
선형 회귀 함수의 수학식:

여기서 xi는 독립 변수, y는 종속 변수, y의 값 영역은 (-Ø,Ø), θ0은 상수 항, θi(i=1,2,…,n)는 요구 계수, 다른 가중치 θi는 종속 변수에 대한 독립 변수의 다른 기여 정도를 반영합니다.우리가 중학교에서 배운 일원 1차 방정식 y=a+bx, 하나의 독립변수와 하나의 종속변수만을 포함하는 회귀분석을 일원 선형 회귀분석이라고 합니다.중학교에서 배운 이원 1차 방정식은 y=a+b1x1+b2x2, 삼원 1차 방정식은 y=a+b1x1+b2x2+b3x3이며, 이 회귀 분석에는 다중 선형 회귀 분석이라고 하는 두 개 이상의 독립 변수가 포함됩니다.일원 선형 회귀 분석이든 다중 선형 회귀 분석이든 모두 선형 회귀 분석입니다.
2. 논리함수 (Sigmoid 함수)
2.1 논리 함수의 수학적 표현

2.2 논리 함수의 그림

그림 1 시그모드 함수의 대략적인 그림
그림 1에서 z가 -Ø, g(z)가 0, z가 Ø, g(z)가 1인 경향이 있으며 함수의 값 임계값은 (0,1)임을 알 수 있다.원리는 z가 -,, ,, g(z)가 0, z가 ,, 0, g(z)가 1인 경향이 있습니다.동시에 z가 5인 경향이 있을 때 g(z)의 값이 0.99 부근에 도달하고 z가 클수록 g(z)가 1인 경향이 있음을 알 수 있습니다.우리가 평소에 부딪힐 확률을 생각해보면 내일 비가 올 확률은 0.3, 맑을 확률은 0.7이라고 생각할 수 있습니다.동전 하나를 던질 확률도 0.5, 반대일 확률도 0.5다.확률도 0에서 1 사이의 일부 수로 sigmod 함수의 값 영역을 확률과 연결할 수 있습니다.
2.3 논리함수의 도함수
논리 함수의 표현식은 다음과 같다.
도함수는 다음과 같다.


다음과 같이 변환할 수 있습니다

위의 추론에서 로지스틱 함수의 도함수는 자체 표현식으로 변환할 수 있음을 알 수 있으며, 이는 나중에 기울기 하강 방법을 사용하여 매개변수를 풀 때 사용되며 먼저 인상될 수 있습니다.이 섹션의 논리 함수에 대한 소개에서 논리 함수는 값 도메인이 (0,1)인 연속적이고 임의의 차수로 유도 가능한 함수임을 알 수 있습니다.
3. 로지스틱 회귀 함수
로지스틱 회귀 함수를 도출하는 단계는 로지스틱 회귀의 기원 기사에서 자세히 도출되었으며, 로지스틱 회귀의 종속 변수 g(y)가 베르누이 분포에서 샘플이 1일 확률이라는 것도 알려져 있습니다.로지스틱 회귀의 원리는 로지스틱 함수를 사용하여 선형 회귀의 결과를 (-Ø,Ø)에서 (0,1)로 매핑하는 것이라고 이전에 언급했습니다.우리는 위의 문장을 공식으로 묘사한다

선형 회귀 함수의 결과 y를 sigmod 함수에 넣으면 로지스틱 회귀 함수가 생성됩니다.y의 값 영역과 sigmod 함수의 값 영역에서 선형 회귀의 결과(-Ø,Ø)는 로지스틱 회귀 함수의 sigmod 함수로 (0,1)에 매핑되며, 이 결과는 확률 값과 유사합니다.로지스틱 회귀 함수를 다음과 같이 변환합니다
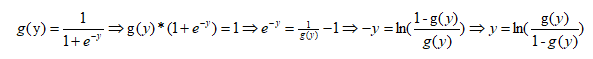
위의 식에서 로지스틱 회귀의 결과 g(y)를 어떤 사건이 일어날 확률로 본다면, 이 사건이 일어나지 않을 확률을 1-g(y)라고 하며, 이 둘의 비율을 확률(odds)이라고 한다.g(y)=p라고 하면 다음 공식을 얻을 수 있습니다.

즉, 선형 회귀의 결과는 로그 확률과 동일합니다.자동차 대출에서 채무불이행(기한 내 상환하지 않아 대손 발생) 고객의 샘플 라벨을 1로 정의하면 정상(기한 내 상환) 고객의 샘플 라벨을 0으로 정의합니다.논리 함수의 값은 고객 디폴트의 사후 확률로 정의될 수 있습니다

역사적으로 채무불이행 고객 및 정상 고객의 연령, 급여, 주택 대출, 제3자 플랫폼에서 빌린 금액 등 많은 수의 계약 위반 고객 및 정상 고객에 대한 샘플 데이터가 축적되었다.이러한 라벨은 로지스틱 회귀 함수의 xi이며 이러한 샘플 데이터를 사용하여 로지스틱 회귀 모델을 훈련하고 변수 x의 매개변수(계수) θ를 풀 수 있습니다.라벨 데이터의 연령, 급여 등은 기존 정보이며 매개변수(계수)θ도 이미 구한 경우 라벨 데이터와 매개변수를 로지스틱 회귀 모델에 대입하면 고객이 계약을 위반할 확률을 예측할 수 있습니다.그럼 로지스틱 회귀 모델의 매개변수를 어떻게 해결합니까?두 번째 장에서 간략하게 설명하면 파이썬에 이미 있는 캡슐화 함수가 있으므로 직접 호출할 수 있습니다.
2. 로지스틱 회귀 분석의 매개변수를 어떻게 해결합니까?
1. 극대우도함수
먼저 작은 예를 들어보자: 만약 샤오화가 이번 시험에서 90점 이상을 받으면 엄마는 99%가 샤오화에게 휴대폰 하나를 보상하고 90점 이상을 받지 못하면 엄마는 99%가 샤오화 휴대폰을 보상하지 않을 것이다.지금 샤오화(小没有得到)는 휴대전화를 받지 못해서 샤오화(小这次)에게 이번에 90점을 받았냐고 물었다.아마도 우리의 첫 반응은 샤오화(小大概)가 90점 이상을 받지 못했다는 것입니다.알려진 샘플 결과를 사용하여 이러한 결과로 이어질 가능성이 가장 높은 매개변수 값을 역추정하는 것은 최대 가능성 추정입니다.
로지스틱 회귀 함수와 결합하여 우리가 이미 대량의 계약 위반 고객과 정상 고객의 샘플 데이터를 축적하고 최대 가능성 함수를 사용하여 과일 추적 요인으로부터 현재 결과의 가능성을 최대화하는 매개변수(계수) θ를 추정하면 매개변수가 있으면 모든 고객이 계약을 위반할 확률을 구할 수 있습니다.우리는 위에서 고객의 계약 위반에 대한 사후 확률을 언급한 적이 있습니다.

그에 따라 고객이 계약을 위반하지 않을 확률을 얻을 수 있습니다.

만약령

계약 위반의 사후 확률은 다음과 같이 쓸 수 있습니다.

위약하지 않은 사후 확률은 다음과 같이 쓸 수 있다

어떤 고객의 경우, 우리는 샘플 데이터(x,y)를 수집했습니다.이 샘플에 대해 그의 레이블이 y일 확률은 다음과 같이 정의할 수 있습니다.
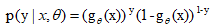
그 중 y {{0,1}.y=0일 때 위 식은 위약하지 않을 사후 확률이고, y=1일 때 위 식은 위약 사후 확률입니다.현재 우리는 m개 고객의 관측 견본을 가지고 있다

각 샘플이 발생할 확률을 곱하면 이 합성을 통해 얻은 합 사건이 발생할 총 확률(확률의 곱셈 공식 사용), 즉 우도 함수로 다음과 같이 쓸 수 있습니다

여기서 θ는 원하는 매개변수입니다.비고: 우리는 항상 현재 결과가 나타날 가능성이 가장 높기를 원하므로 극대화된 우도 함수에 해당하는 매개변수 θ를 얻기를 원합니다.쉽게 풀 수 있도록 함수의 단조성을 변경하지 않는 대수 함수 ln을 도입하고 연승을 덧셈으로 변환하여 대수 우도 함수를 얻습니다

지금까지 기울기 상승 방법을 사용하여 로그 우도 함수를 풀고 현재 결과의 가능성이 가장 높은 매개변수 θ를 찾을 수 있습니다.로그 우도 함수는 손실 함수를 구성하는 데 사용할 수 있으며 기울기 하강 방법을 사용하여 손실을 최소화하는 매개변수 θ를 구하고 다음으로 로지스틱 회귀에서 손실 함수를 볼 수 있습니다.참고: 로그 우도 함수를 사용하면 연승이 덧셈으로 바뀌어 쉽게 풀 수 있을 뿐만 아니라 로그 우도 함수에 해당하는 손실 함수는 미지의 매개변수에 대한 고차 연속 유도 볼록 함수로 전역 최적해를 구하는 데 편리합니다.
2. 구조손실함수
기계학습에는 손실함수의 개념이 있는데, 손실함수는 일반적으로 예측값과 실제값의 차이로 정의된다는 것을 알고 있는데, 예를 들어 샤오화가 이번 시험에서 98점을 맞을 것으로 예측하고, 성적이 나오면 샤오화는 실제로 97점을 받았고, 샤오화의 성적 예측값과 실제값의 차이는 1이며, 이 1 통속적인 이해는 손실함수의 값이다.
위의 사례를 통해 손실 함수가 작을수록 모델의 예측이 정확함을 알 수 있습니다.따라서 함수가 비교적 복잡하고 결정해(해석해)가 없거나 결정해(근사해)를 구하기 어려운 경우 일반적으로 수치해(근사해)를 구한다.일반 모델은 손실 함수를 최소로 대응하는 매개변수 θ를 구할 수 있습니다.로지스틱 회귀 분석의 극대 우도 함수와 결합하여 전체 데이터 세트에서 평균 로그 우도 손실을 취하면 다음과 같이 얻을 수 있습니다

여기서 J(θ)는 로그 우도 함수 앞에 음의 부호를 추가하여 평균을 낸 손실 함수입니다.즉, 로지스틱 회귀 모델에서 최대화 우도 함수와 최소화 손실 함수는 실제로 동등합니다(최대화 대수 우도 함수에 해당하는 매개변수 θ와 최소화된 평균 대수 우도 손실에 해당하는 매개변수 θ가 일치합니다).

그럼 어떻게 손실 함수의 최소 대응 매개변수를 구합니까?다음 절에서 설명하는 방법인 기울기 하강법을 사용할 수 있습니다.
3. 기울기 하강법으로 매개변수를 풀다
먼저 한 사람이 산을 내려오는 것을 예로 들어 구배 하강법의 단계를 설명한다.
step1 현재 자신의 위치를 명확히 한다.
step2: 지금 있는 위치가 가장 빨리 내려가는 방향을 찾아라.
step3: 두 번째 단계에서 찾은 방향으로 한 단계 더 나아가 새로운 위치에 도달한다. 새로운 위치는 이전 위치보다 낮다.
step4: 산을 내려올지 여부를 판단하고, 1단계를 계속하고, 1단계에 도달하지 않은 경우 중지한다.
위의 분석에서 기울기 하강 방법을 사용하여 매개변수를 해결하는 가장 중요한 것은 가장 빠르게 하강하는 방향을 찾고 나아갈 단계를 결정하는 것임을 알 수 있습니다.
그렇다면 함수가 가장 빨리 떨어지는 방향은 무엇입니까?
만약 일원 함수의 미분수를 배운 적이 있다면, 미분수의 기하학적 의미는 특정 접선의 기울기라는 것을 알아야 한다.또한 도함수는 해당 지점에서 함수의 변화율을 나타낼 수 있으며, 도함수가 클수록 해당 지점에서 함수의 변화가 커집니다.

그림 2 곡선의 도함수
그림 2에서 p2점의 기울기가 p1점의 기울기보다 크다는 것을 알 수 있으며, 즉 p2점의 도함수가 p1점의 도함수보다 크다는 것을 알 수 있다.다차원 벡터의 경우

그것의 도함수를 구배(편도함수)라고 하는데, 어떤 변수의 도함수를 구할 때, 다른 변수를 상수로 간주하여, 전체 함수에 대하여 도함수를 구한다. 즉, 그것의 각 성분에 대하여 각각 도함수를 구한다

함수의 특정 지점에 대해 기울기는 해당 지점에서 시작하여 함수 값이 가장 빠르게 변하는 방향을 나타냅니다.지금까지 기울기 하강 방법으로 매개변수를 푸는 방향이 발견되었는데, 그것이 함수의 기울기 방향이다.다음으로 손실 함수의 기울기(편도함수)를 유도하는데, 손실 함수의 공식으로 알 수 있다.

지금까지 기울기 하강 방향을 찾았고, 주어진 단계만 있으면 반복 방식으로 원하는 매개변수를 구할 수 있으며 반복 공식은 다음과 같습니다

참고: 현재 위치의 θ를 -에 대입하여 얻은 값은 이 지점에서 기울기가 떨어지는 단계입니다.
이 중 a는 학습률로 0보다 큰 수로 단계 길이가 아닌 특정 방향으로 얼마나 멀리 가는지 제어할 수 있다.F는 방향이고 F는 다음과 같이 나타낼 수 있다

반복 공식은 다음과 같이 더 쓸 수 있습니다

그럼 언제 반복이 멈추나요?
일반적으로 반복이 일정 횟수에 도달하거나 학습 곡선이 특정 임계값보다 작으면 반복을 중지합니다.sklearn 라이브러리에서 Logistic Regression을 호출할 때 일반적으로 기본 매개변수 tol=0.0001, 최대 반복 횟수 max_iter=100을 취하면 됩니다
'개발 꿀팁 > PYTHON' 카테고리의 다른 글
| 파이썬의 다양한 방법 목록 (0) | 2022.11.24 |
|---|---|
| 파이썬 유도식 (0) | 2022.11.23 |
| Python 하늘에 가득한 눈송이를 그리다 (0) | 2022.11.23 |
| 파이썬 데이터 분석 - 데이터 업데이트 (0) | 2022.11.23 |
| 파이썬 데이터 분석-애플리케이션 함수 (0) | 2022.11.23 |